Nearest Neighbor Classification
Nearest Neighbor Classification
Procedures
- Assemble a data set (training set)

- How to classify a new image x?
- find its closest neighbor y, and label it the same
Notes:
- training set of 60000 images
- test set of 10000 images
How do we determine if two data (images) are closest?
With 28 x 28 image, we can strech it to become a vector of 784.

We then use Euclidean distance formula to find the distance betwen them.
$$||x - z|| = \sqrt{\sum_{i=1}^{784}(x_i - z_i)^2}$$
With 1 closest neighbor, we are getting 3.09% on the test set.
Ideas for Improvement
- Choose different number of neighbors (kNN instead of 1NN)
- Better distance functions
With different K
| k | 1 | 3 | 5 | 7 | 9 | 11 |
|---|---|---|---|---|---|---|
| Test Error % | 3.09 | 2.94 | 3.13 | 3.10 | 3.43 | 3.34 |
With different distance functions
There are many active researches on accodmading the translations, rotations and deformation.
For example, the 1 in the right is generated by shifting 1 in the left by few pixel.
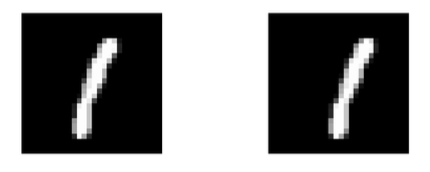
| dist function | l2 | tangent distance | shape context |
|---|---|---|---|
| error rate | 3.09 | 1.10 | 0.63 |
Problem
The curse of Dimension
Although the kNN search provides very good algorithm, the search time is slow. It takes time proportion to the size of data, n, and dimension, d, O(nd).
Ideas for addressing the issues:
- Different Data Structure
- Locality Sensitive Search #TODO
- Ball Tree #TODO
- K-d tree #TODO
- Different distance function
- Approximate Distance (link) #TODO
- Data Reduction
k-d Tree
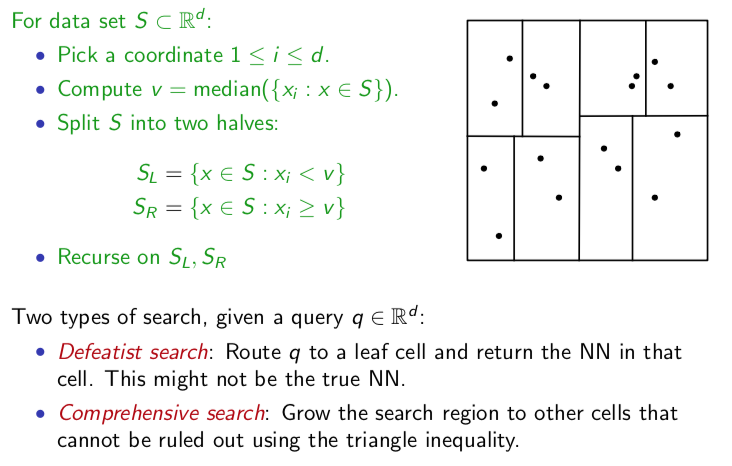
Credit to CSE 250 Class notes.